In the 1860s, English economist William Jevons noticed something unexpected. As steam engines became more efficient, i.e., used less coal to do the same work, coal consumption didn’t fall. It rose.
Why? Because the shift in efficiency made steam power cheaper to use. And when something gets cheaper, people use it more. Steam engines spread across industries, and powered more machines, more factories, more systems.
As a result, total coal use, demand, and costs soared. This contradiction, that improvements in efficiency can actually increase total demand, and by extension, the cost, is now known as Jevons Paradox.
We’re seeing a similar story unfold in artificial intelligence (AI). As agentic AI models get better at solving complex tasks, we don’t use them less; we use them more. Eventually, intelligence will be “too cheap to meter.”
In the same vein, agentic AI systems are rapidly shifting from simply recalling answers from pre-trained knowledge to actively “thinking hard” during each interaction. By exploring multiple reasoning paths on the fly, these models will move beyond memorized responses and deliver more adaptive and reliable AI conversations.
Put simply, this redefines our expectations of what technology can achieve. As test-time scaling becomes the standard, users will expect AI agents that learn from each exchange and adapt to new challenges in real time.
What is test-time scaling?
Test-time scaling is the concept of using more compute (by running models for longer, using more powerful hardware, or sampling more responses) during inference, when a trained model is deployed and generating outputs. The goal is to improve performance without retraining or changing the model’s architecture, and it’s typically used for complex tasks like reasoning and multi-step problem solving.
In simpler terms: instead of retraining the model to make it smarter, you give it more time or resources to think when it’s actually being used. This can mean using more samples in a language model, running deeper searches, or using larger ensembles.
These are all techniques that make the model perform better at test time, even though it hasn’t “learned” anything new. On the flip side, the more efficient and capable models become, the more we rely on them—and the more compute we use in the process.
Test-time scaling is part of the broader field of AI scaling laws, which explore how adding compute at different stages—training, post-training, and inference—affects a model’s performance.
The 3 underlying AI scaling laws
Let’s zoom out a bit.
AI scaling laws are empirical patterns that show how model performance tends to improve as you scale up model size, dataset size, and compute. The relationship usually follows a power law, as in, performance increases with scale, but with diminishing returns.
These laws are useful because they give you a framework to figure out how to allocate resources, whether that’s compute, data, or model parameters, to get the most out of an AI system without overspending.
There are three types of scaling laws in AI, and each has distinct uses. Let’s take a look at them below.
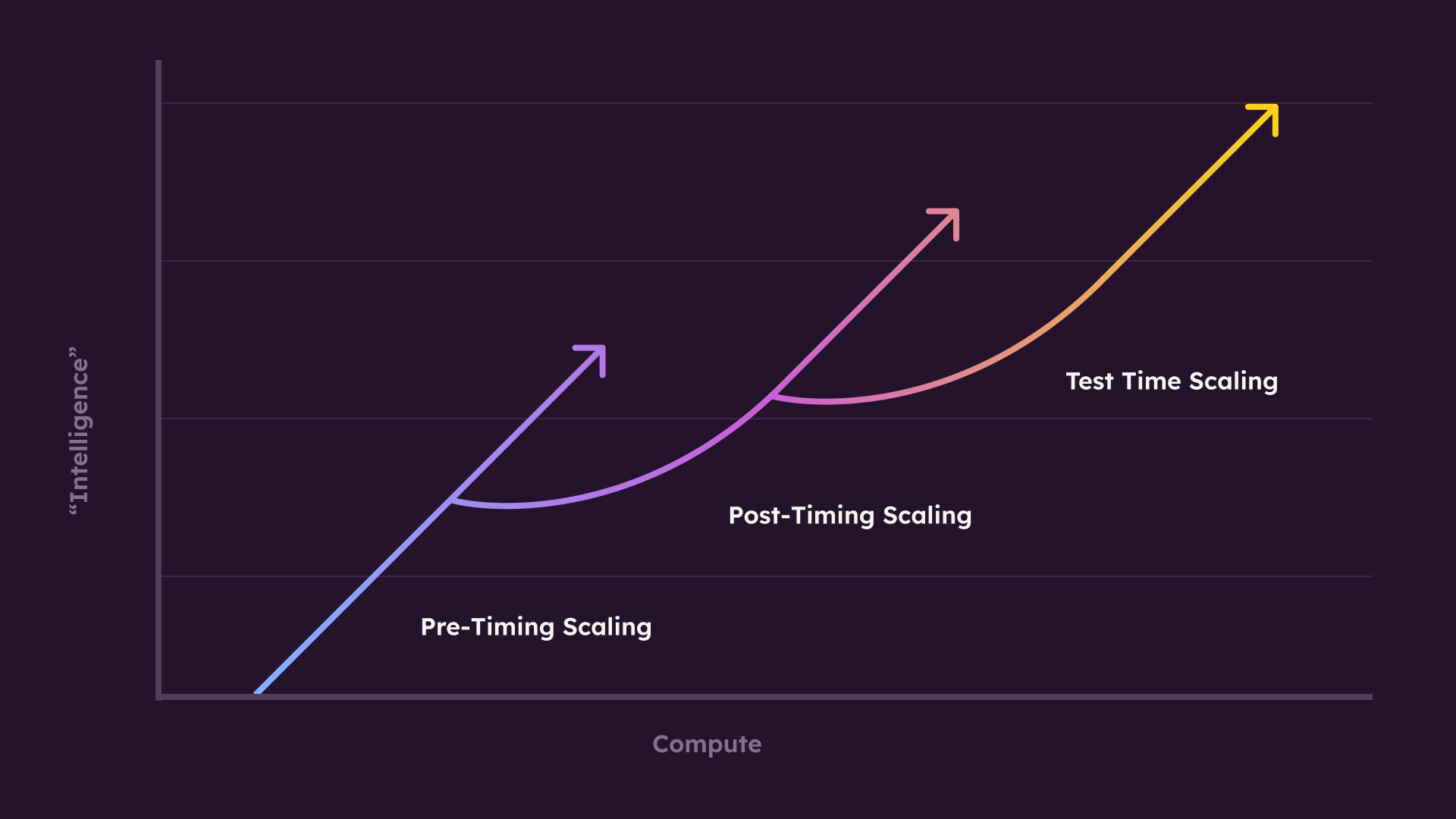
1. Pre-training scaling
This focuses on building increasingly larger foundation models by training them on massive datasets. This approach allows the model to learn broad language patterns and world knowledge in one comprehensive phase, as seen in systems like GPT-3.
While scaling up pre-training improves conversational capabilities, it also demands substantial computing resources and can limit adaptability to complex or novel queries once the training is complete. Even with broad exposure during training, the model may still struggle to reason through tasks that require deeper context, multiple steps, or up-to-the-moment judgment.
2. Post-training scaling
Post-training scaling refines these large pre-trained models by tailoring them for specialized purposes. Developers can enhance a model’s performance using additional data or specific training objectives, such as improving customer service interactions or handling sensitive content, i.e., fine-tuning.
Approaches like GPT-3.5 fine-tuning and Reinforcement Learning from Human Feedback (RLHF) highlight how post-training adjustments can boost accuracy and reduce harmful outputs (like biased language, misinformation, or toxic responses in sensitive topics). Yet, these methods can still be limited if the model faces scenarios outside its newly “specialized” domain, requiring repeated updates to stay current in ever-changing environments.
3. Test-time scaling
Test-time scaling adds a new layer of flexibility, allowing models to “think hard” in real time when confronted with challenging or unfamiliar prompts. Models like ChatGPT o3, for instance, can reason through multiple paths at inference, backtrack if necessary, and arrive at conclusions that aren’t strictly based on memorized knowledge.
This dynamic approach paves the way for more adaptive and robust conversations, opening doors to advanced problem-solving.
However, it also requires more compute at runtime, so it’s important to balance that extra power with response speed to keep things efficient and cost-effective. Since you’re tapping more compute during inference, response times can slow down, making latency a potential blocker in real-time use cases like voice, chat, or search. For these applications, every millisecond matters, so optimizing for low-latency performance matters just as much as getting the answer right.
Test-time scaling improves real-time reasoning in conversations
Agentic AI systems often rely on one massive model to handle every request, which drives up costs. Plus, it doesn’t always deliver the most accurate outputs. Without any structure for checking or revising its own outputs, the system risks hallucinating, oversimplifying, or getting stuck on the wrong track.
Test-time scaling, however, introduces a new approach: a smaller model generates answers, while an additional “judge” model checks these answers for consistency and accuracy.
This structure does add some extra computation at inference, but overall, it can be faster and cheaper than running a single huge model for all queries. In fact, in scenarios where a smaller base model had moderate success, applying additional test-time computation enabled it to outperform a model 14 times bigger, showing just how powerful this approach can be.
Smarter orchestration means better customer experiences
Consumers, of course, care less about how resources are used and more about whether the AI delivers accurate, helpful responses. With a second model acting as a judge at test time, errors or hallucinations can be caught before reaching the user.
In customer experience (CX), test-time scaling translates to fewer escalations, smoother conversations, and better customer satisfaction, without the need to constantly retrain or overbuild large models.
This also unlocks a smarter way to handle complex interactions.
Not every query needs a heavy-duty response, so a lightweight model can handle the simple tasks quickly. But when a request is ambiguous, high-stakes, or just hard to answer, that same model can switch to an asynchronous test-time scaling flow: pausing the conversation, running deeper reasoning in the background, and returning a more accurate response once ready.
That kind of orchestration, as in, deciding when to switch between models, and how, is what makes the system both cost-efficient and customer-friendly. And it’s key to delivering AI that feels reliable, responsive, and trustworthy at scale.
This shift toward test-time scaling means developers can fine-tune their systems for both efficiency and quality. The slight increase in latency from running two models is often a worthwhile trade-off for better accuracy.
Ultimately, this setup delivers the kind of reliable, high-quality interaction that consumers expect, proving that a blend of smart architecture and dynamic validation can transform how we think about AI performance and user satisfaction.


